About
What is Python?
Simply put, Python is a programming language. Python is considered a very sraightforward language due to its syntax and readability. In addition, the progam has a wealth of support for packages that allow a large amount of flexibility. Python is freely distributed and accessible.
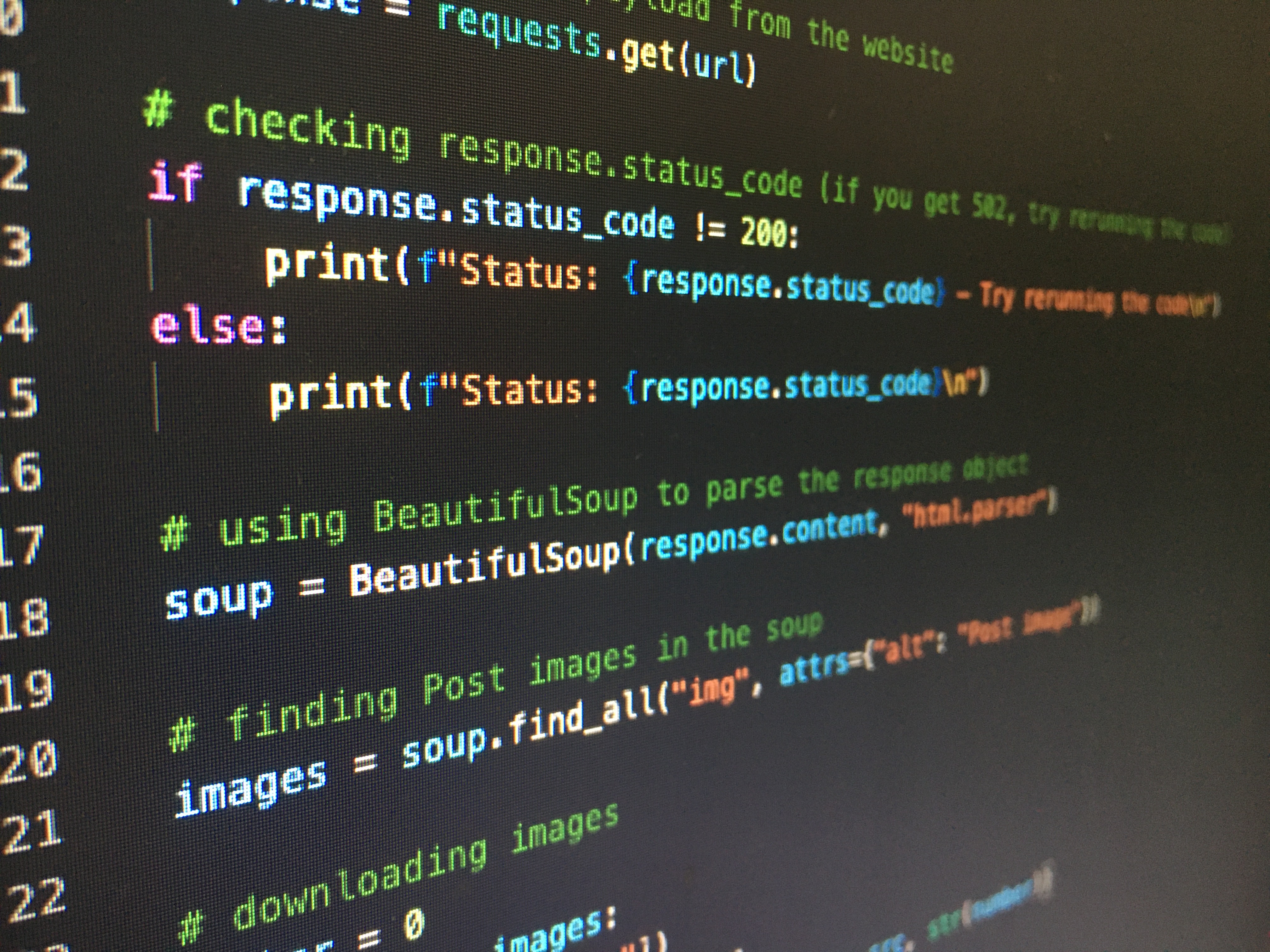
Python is one of the most popular programming languages in the world. Often, this is one of the first programming languages that people start to learn with. Since Python is a general-purpose language, it may be used for a variety of tasks. One of the best uses of Python is through web scraping.
Use
What is Web Scraping?
The process of extracting data from a webpage is known as web scraping. This data is gathered and then exported in a way that the user will find more valuable. A spreadsheet or an application programming interface.
Web scraping is legal when done correctly. There are some guidelines that must be followed. Scraping a website becomes unlawful when data is retrieved that is private information. With that in mind, be careful with how you use web scraping.